La définition du Big Data et ses enjeux !

Contexte lié à l’avènement de l’analyse de grandes bases de données :
-
Les capacités actuelles de mesure (mesure en temps réel, omniprésence de capteurs) et de traitement de données (pouvoir de calcul des ordinateurs de plus en plus élevé), ainsi que de stockage de l’information (grandes capacités de stockage, notamment sur le cloud) permettent la création de grands jeux de données (dénommés « Big data »).
-
Ces données nécessitent l’utilisation de méthodes analytiques spécifiques pour extraire et analyser de l’information pertinente et ainsi générer de la valeur pour leur utilisateur.
-
Concrètement, le but de ces analyses est de construire un modèle reflétant fidèlement le système étudié afin de prédire le résultat de situations ultérieures, ce modèle étant opéré par ordinateur (machine learning). MuZero est l’exemple paradigmatique du machine learning : développé par la société britannique DeepMind, MuZero est un programme informatique opérant en autonomie, et dont l’objectif est de maîtriser des jeux variés sans en connaître les règles originellement, MuZero les apprenants par lui-même.
-
L’analyse de grands jeux de données, le machine learning et l’intelligence artificielle sont aujourd’hui des leviers puissants pour le développement de tout type d’activité, et peuvent être implémentés tout au long du cycle de vie du produit : en recherche et développement dans le but d’accroître les connaissances liées au système étudié, mais également en qualité et contrôle des processus, dans le but d’assurer une performance optimale.
Eléments de définitions & opportunités : Big data, Data mining et Machine learning
Big data
-
Le terme Big data (mégadonnées en français) récapitule 3 grandes caractéristiques :
-
Un grand volume de données
-
Une grande variété de données (nombreuses variables présentes, de nature, magnitude et variance différentes)
-
Une grande vélocité des données (vitesse et fréquence d’acquisition des données élevées)
La plupart du temps, le Big data concerne des données observées, par opposition aux données construites expérimentalement. Ainsi, n’étant pas obtenues à la suite d’un plan d’expériences structurées, les Big data peuvent contenir un certain degré de covariance et de ce fait de corrélation. Cela peut nuire à la compréhension et à la recherche de la relation de causalité dans la performance du processus étudié.
Data mining (information extraction)
-
Le Data mining a pour objet l’extraction d’un savoir ou d’une connaissance à partir de grandes quantités de données, par des méthodes automatiques ou semi-automatiques.
Machine learning
-
Arthur Samuel, considéré comme un pionnier du machine learning, a donné une définition de ce terme en 1959 : « Le champ d’étude qui donne aux ordinateurs la capacité d’apprendre sans être programmés de manière explicite ».
-
La machine informatique apprend/construit des connaissances à partir de données.
La clé de l’implémentation réussie des outils de modélisation et d’analyses prédictives : Good modeling practices
Projet porté par le programme ESPRIT de l’Union Européenne, le Cross-Industry Standard Process for Data Mining (CRISP-DM) est un modèle de processus standard pour la réalisation de projet de Data mining.
Divisé en 6 étapes, ce modèle récapitule les grandes étapes permettant, en partant du besoin (compréhension du métier), de fournir une solution adaptée au sein de l’organisation (déploiement).
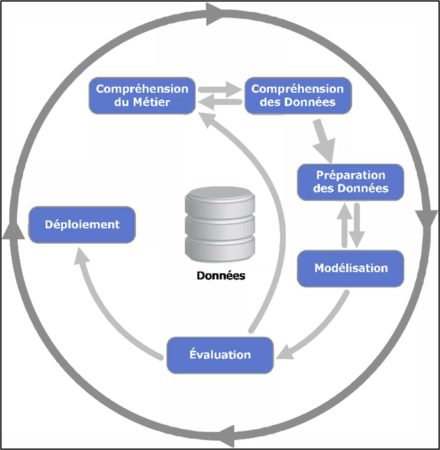
De manière plus détaillée, les étapes du CRISP-DM sont :
-
Compréhension du Métier – quel gain le data mining peut-il apporter ? -> Management de projet
-
Compréhension des Données – quelles sont les données disponibles ? -> Visualisation de données
-
Préparation des Données – fusion, tri, traitement des données manquantes :
-
Le plus important
-
Le plus long (50-70% du temps de projet)
-
Modélisation – quel(s) modèle(s) est/(sont) le(s) plus approprié(s) pour répondre à l’objectif du projet ?
-
Évaluation – modèle(s) final/(finaux) et information(s) obtenue(s)
-
Déploiement – faire bénéficier l’organisation du travail de data mining
Aujourd’hui & en pratique, de nombreux outils sont à disposition !
Les techniques et types de modélisation sont aujourd’hui très nombreuses et en constante évolution, les champs d’étude du Data mining et Machine learning étant très dynamiques :
-
Régression
-
Classification
-
Réduction de dimensions
-
Neural networks
-
Clustering
-
Systèmes de recommandations
Une seule de ces techniques ne pouvant modéliser toutes les situations (no free lunch theorem), et chaque technique présentant des limitations, des approches hybrides sont également utilisées.
Perspectives et conclusion
Les opportunités créées grâce au Data mining et au Machine learning sont nombreuses : elles sont source d’une transformation des organisations et un levier de croissance.
La mise en place de modèles reflétant l’entièreté d’un processus afin de poursuivre le but du zéro défaut (Digital twin), l’implémentation du machine learning dans les microcontrôleurs omniprésents (reconnaissance vocale par exemple), et la prédiction de l’adhésion d’un client à un programme ne sont que quelques exemples d’aide à la décision permise par le Data mining et le Machine learning. De plus en plus précis, ces outils ouvrent le champ des possibilités pour tout type d’activité !
Vous souhaitez interpréter des mégadonnées/Big data via des méthodes analytiques dédiées et ainsi générer de la valeur pour vos utilisateurs/clients? C’est le défi que relève l’ARIAQ en proposant dans son catalogue de formation le cours de « Modélisation et analyse prédictives ».
Hugo Johan – Formation et conseil en Analyses de données
 Ingénieur en Biotechnologie de formation, Hugo est spécialisé en purification de biomolécules (DSP), ayant acquis une expérience de près de 8 ans au sein de laboratoires R&D publiques et privés en Belgique, aux Pays-Bas et en Suisse. Au cours de sa carrière, Hugo a contribué aux développements de biomolécules variées impliquées dans des essais cliniques de Phase I à III (anticorps monoclonaux, bispécifiques, vecteurs viraux), et dans le cadre des normes internationales (GMP/GLP, QbD/PAT/ICH). En parallèle de son cursus en génie biologique, Hugo a développé des compétences en statistiques appliquées, en modélisation et en programmation, devenant le référent de ces thématiques et contribuant à l’implémentation de ces outils au sein des groupes de travail dans lesquels il a évolué.
Ingénieur en Biotechnologie de formation, Hugo est spécialisé en purification de biomolécules (DSP), ayant acquis une expérience de près de 8 ans au sein de laboratoires R&D publiques et privés en Belgique, aux Pays-Bas et en Suisse. Au cours de sa carrière, Hugo a contribué aux développements de biomolécules variées impliquées dans des essais cliniques de Phase I à III (anticorps monoclonaux, bispécifiques, vecteurs viraux), et dans le cadre des normes internationales (GMP/GLP, QbD/PAT/ICH). En parallèle de son cursus en génie biologique, Hugo a développé des compétences en statistiques appliquées, en modélisation et en programmation, devenant le référent de ces thématiques et contribuant à l’implémentation de ces outils au sein des groupes de travail dans lesquels il a évolué.

 +41 24 423 96 50 | Horaires
+41 24 423 96 50 | Horaires